NVIDIA Blackwell: nuevo estándar en arquitectura para IA generativa
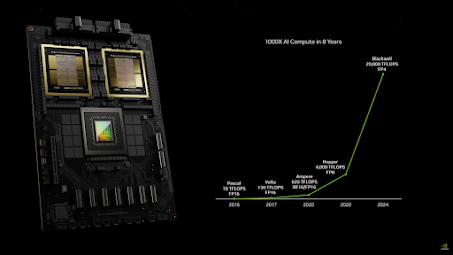
En la última ronda de pruebas comparativas de la industria MLPerf, Inference v4.1, las plataformas NVIDIA ofrecieron un rendimiento líder en todas las pruebas del centro de datos. La primera presentación de la próxima plataforma NVIDIA Blackwell reveló hasta 4 veces más rendimiento que la GPU NVIDIA H100 Tensor Core en la carga de trabajo LLM más grande de MLPerf, Llama 2 70B, gracias al uso de un Transformer Engine de segunda generación y FP4 Tensor Cores.

La GPU NVIDIA H200 Tensor Core entregó resultados sobresalientes en todos los puntos de referencia en la categoría de centros de datos, incluida la última incorporación al punto de referencia, la mezcla de expertos (MoE) LLM Mixtral 8x7B, que presenta un total de 46,7 mil millones de parámetros, con 12,9 mil millones de parámetros. activo por token.
Los modelos MoE han ganado popularidad como una forma de aportar más versatilidad a las implementaciones de LLM, ya que son capaces de responder una amplia variedad de preguntas y realizar tareas más diversas en una sola implementación.
También son más eficientes ya que sólo activan a unos pocos expertos por inferencia, lo que significa que entregan resultados mucho más rápido que los modelos densos de un tamaño similar.
El crecimiento continuo de los LLM está impulsando la necesidad de más computación para procesar las solicitudes de inferencia. Para cumplir con los requisitos de latencia en tiempo real para atender a los LLM de hoy,
y para hacerlo para la mayor cantidad de usuarios posible, la computación con múltiples GPU es imprescindible. NVIDIA NVLink y NVSwitch brindan comunicación de gran ancho de banda entre GPU basada en la arquitectura NVIDIA Hopper y brindan importantes beneficios para la inferencia de modelos grandes rentables y en tiempo real.
La plataforma Blackwell ampliará aún más las capacidades de NVLink Switch con dominios NVLink más grandes con 72 GPU. Será una ampliación clave para todos los colaboradores, incluyendo los principales 10 socios de NVIDIA: ASUSTek, Cisco, Dell Technologies, Fujitsu, Giga Computing, Hewlett Packard Enterprise (HPE), Juniper Networks, Lenovo,
Innovación de software implacable:
Las plataformas NVIDIA se someten a un desarrollo de software continuo, acumulando mejoras de rendimiento y funciones mensualmente. La GPU NVIDIA H200 entregó hasta un 27% más de rendimiento de inferencia de IA generativa respecto a la ronda anterior, lo que subraya el valor agregado que los clientes obtienen con el tiempo de su inversión en la plataforma NVIDIA.
Triton Inference Server, parte de la plataforma NVIDIA AI y disponible con el software NVIDIA AI Enterprise, es un servidor de inferencia de código abierto con todas las funciones que ayuda a las organizaciones a consolidar servidores de inferencia específicos del marco en una plataforma única y unificada.
Esto ayuda a reducir el costo total de propiedad de servir modelos de IA en producción y reduce los tiempos de implementación de modelos de meses a minutos.
En esta ronda de MLPerf, Triton Inference Server entregó un rendimiento casi igual al de las presentaciones bare-metal de NVIDIA, lo que demuestra que las organizaciones ya no tienen que elegir entre usar una plataforma de producción rica en funciones de inferencia de IA de grado superior y lograr un rendimiento máximo.
Obtenido de : https://blogs.nvidia.com/blog/mlperf-inference-benchmark-blackwell/
Conoce más sobre la nueva arquitectura de NVIDIA: https://www.nvidia.com/es-la/data-center/technologies/blackwell-architecture/



Comentarios
Publicar un comentario